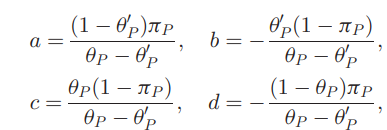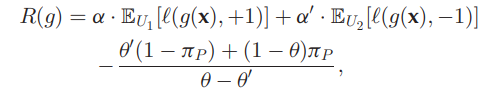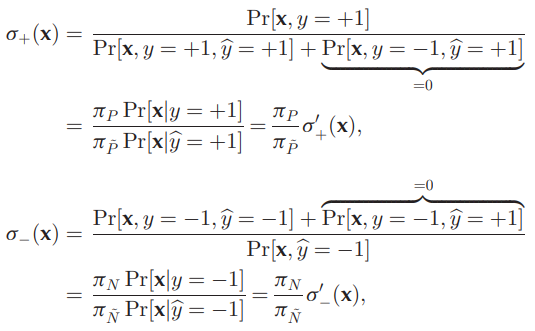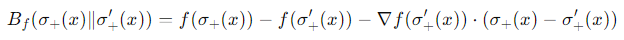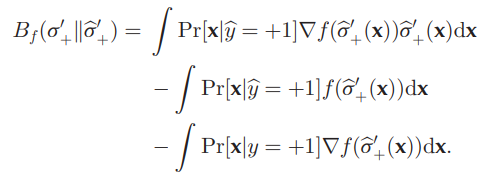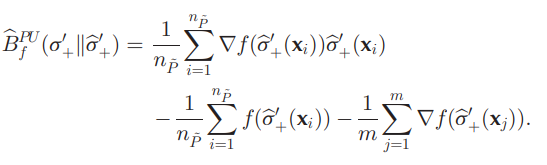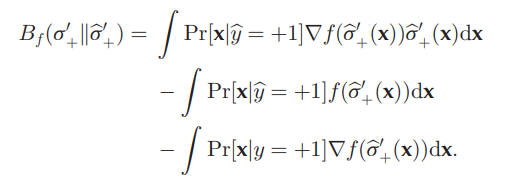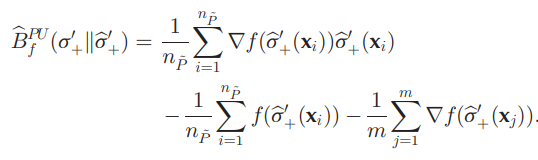https://ieeexplore.ieee.org/document/9361098
2019年にeもKDDに出している。
Introduction
この論文は以下の3点の貢献がある。
- PU Learningしていくときに、時たま出るおかしな予測について、学習アルゴリズムの「ノイズ」のせいだとしている。そして、それを補正していきたい。
- それについての、超過リスク分析?に基づく新しい手法を提案した。
- 実験で正しさを証明した。
Related Works
📄 2020-Survey-A Survey of Label-noise Representation Learning: Past, Present and Future
2020-Survey-A Survey of Label-noise Representation Learning: Past, Present and Future
📄2020-Survey-Learning from positive and unlabeled data: a survey
Semi-supervised Learningベースの手法もあるらしい。
Importance Weightingベースの方法あるらしい。
UU Learningベースの手法もあるらしい。
問題設定
- サンプルはx∈X、ラベルはy∈{−1,+1}で、+1がP、-1がNデータ。
- PUなので、実際にはyは与えられず、Pは必ずPだがUはPかNかはわからないという設定。
- PUの式は以下の2つである。数学的には等価であるが、下の方がよくつかわれる。
2πPE+[l(g(x),+1)]+EU[l(g(x),−1)]−πPπPE+[l(g(x),+1)]−πPE+[l(g(x),−1)]+EU[l(g(x),−1)] - UU Learningは2つのUnlabeledの分布があり、それぞれClass Priorがπ1,π2であるとき、以下の式の最小化になる。
- まずU1について、lossの合計は係数a,bを使ってal(⋅,+1)+bl(⋅,−1)として、U2についても同様にcl(⋅,+1)+dl(⋅,−1)としている。
- この時、これらを用いてaπ1+dπ2=πP,b(1−π1)+c(1−π2)=πNであるとあらわせる。
- この時、以下のような式でUU Learningできる。
- 問題設定は、以下のようなノイズ。
- 与えられるのはPUのデータセット。
- Pデータは完ぺきにPで構成されている。
- Uデータはいつも通りPとUによって、Class Priorπの混合比である。
- ノイズとは、PU Learningしたときに、時たま明らかにおかしい予測をしてしまう問題を指す。なので、これは「学習アルゴリズム」や「各データ」に依存して起きる。
- これをうまく較正していくのが目標。
提案手法
1. PU LearningでPseudo Labelを付与
PU Learningを用いて、分類器gPUを訓練し、U Dataにそれを用いてPseudo Labelをつけていく。
UにPseudo Labelが付与されたら、Pseudo LabelがPのものの集合はQP、NのものはQNとする。
2. Pseudo Labelの予測結果を補正
Uに対するPseudo Labelが完全に正しいというわけはないので、これをできるだけ是正していきたいと考える。
ここで、下図のようなもともとのσ+.σ−を式変形とπP≈πPˉ,πN≈πNˉの前提をおいて、σ+′,σ−′を代わりに推定しそれでσ+などを代替する。
σ+(x)=1/Pr(y^=+1∣x,y=+1)σ−(x)=Pr(y=−1∣x,y^=−1) σ+′(x)は与えられたPデータによりp(x∣y=+1)は経験分布として既知で、Pseudo LabelのPとなっているものにより、p^(x∣y=+1)を推定する。
σ(x)は与えられたPデータで同様にp(x∣y=+1)は経験分布として既知で、p(x∣y=+1)はわからない。
本来これについてモデルを当てはめたいところだが、次でいうBregman Divergenceの計算でそれは実は不要とわかる。
3. Bregman Divergenceの計算
Bregman Divergenceの定義として、微分可能なfな凸関数を使う、Bregman DivergenceDfは以下のようになる。
Df(p∣∣q)=f(p)−f(q)−⟨∇f(y),x−y⟩ 例えば、f(x)=∣∣x∣∣2となるとき、これは∣∣x∣∣2−∣∣y∣∣2−⟨2y,x−y⟩=2∣∣x−y∣∣2となり、ユークリッド距離になるらしい。
これを今回は、ある関数fによって、Df(σ+∣∣σ+′)を計算する。分布についてのBregman Divergenceは、このように全体を積分していく(期待値
ここでは、以下のようにBregman Divergenceはなるらしい。
これを経験的に解くと、以下の式になる。
これを計算することにより、σ+のp(x∣y^=+1)の値を明確に推定せずとも、σ+の推定値がわかる。
4. 推定したσ(x)を用いた新たなPUの式で再学習
R(g)=γRIAos+(1−γ)RICosRIAos=EPˉ[σ+(x)l(g(x),+1)]+ENˉ[σ−(x)l(g(x),−1)]RIAos=2πPEP[l(g(x),+1)]+EU[l(g(x),−1)] 1つ目の損失はPseudo Labelについて。
2. σ+,σ−の推定
仮定により、与えられるPは完ぺきにCleanなので、QPはPデータと同じ分布に従うはず。だからこの2つの経験分布は距離が最小ひいては0でなければならない。
だが、学習アルゴリズムやデータに依存するNoiseというのがあるため、ここの差異を是正しないといけない。これの一環として、σ+,σ−を推定して、補正を掛ける。
σ+(x)=1/Pr(y^=+1∣x,y=+1)σ−(x)=Pr(y=−1∣x,y^=−1) 以上のように、定義で0になっている部分を足してあげることで、新たな式変形σ+′などができる。
ここでπP/πPˉなどがあるが、実際の推定はこの部分は大体1だとして、直接σ+′(x)=Pr(x∣y=+1)/Pr(x∣y^=+1)などを推定し、これをσ+(x)と等しくなるべきだろう、と考える。
その尺度として、Bregman Divergenceを使っている。
定義として、微分可能なfな凸関数を使う、Bregman DivergenceDfは以下のようになる。
Df(p∣∣q)=f(p)−f(q)−⟨∇f(y),x−y⟩ 例えば、f(x)=∣∣x∣∣2となるとき、これは∣∣x∣∣2−∣∣y∣∣2−⟨2y,x−y⟩=2∣∣x−y∣∣2となり、ユークリッド距離になるらしい。
σ+(x)=p(x∣y=+1)/p(x∣y^=+1)である。与えられているPデータは絶対に正しいp(x∣y=+1)の経験分布ので、動かす必要があるのはp(x∣y^=+1)だけ。
以下のように、推定したいσ+とσ+′の間でBregman Divergenceを考え、最小化するようにσ+を動かしていく。
我々はPU Learningの識別器から、Uの中にあるPseudo LabelがPであるデータに
これと似てるように、σ−の予測はできる。